Day 4 of #30DaysOfTerraform: Why Terraform State Matters (and How Remote Backends Change the Game)
Diving into Cloud and DevOps like a kid who learned cycling yesterday and signed up for a race today. I break things, read error logs like bedtime stories, and slowly figure out how not to repeat the same mistakes. If you enjoy honest tech journeys with a bit of humor, you’ll fit right in.
#30DaysOfAWSTerraform
By Day 4, I already know how to define AWS resources in Terraform and apply them. But real infrastructure work depends on something deeper: state. Terraform’s internal snapshot of your infrastructure determines what exists, what needs to change, and what should be destroyed. Understanding how state works, why it matters, and how to manage it beyond local files becomes a pivot point in any serious Terraform workflow.
If Day 3 was about building resources, Day 4 was about trusting them.
Why Terraform State Matters
At first glance, Terraform seems straightforward: declare resources and let Terraform create them. Under the hood, Terraform needs a way to track infrastructure across runs. It does that through the state file, a structured map of resource metadata that tells Terraform what’s already deployed and how future changes should be applied.
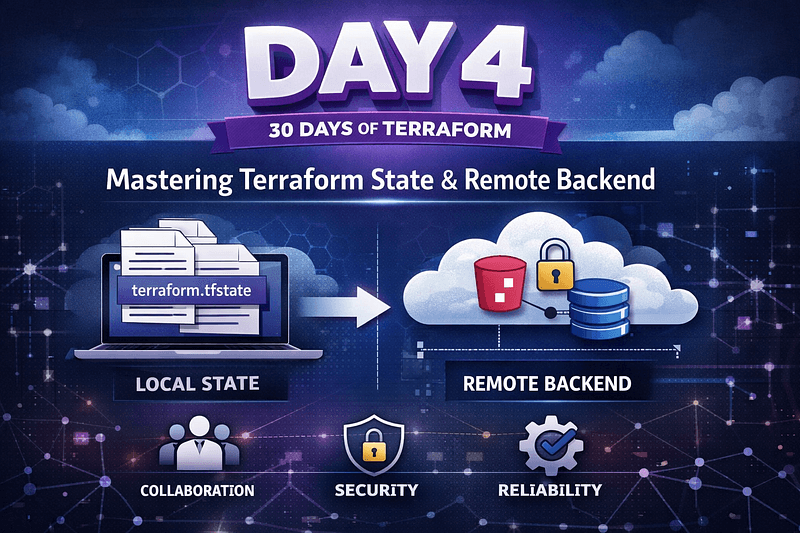
Local state works while you’re experimenting alone. The moment you introduce collaboration, CI/CD pipelines, or long-lived environments, storing state on your laptop stops being viable. On Day 4, I moved that state into AWS using an S3 backend. It’s a small change in configuration, but a major change in how Terraform workflows behave in a team environment.
What Terraform State Really Is
Every terraform apply updates a file called terraform.tfstate. This file maps your HCL configuration to real cloud resources. Think of it as Terraform’s memory. Without it, Terraform would have to guess what exists, and that’s unacceptable in any production environment.
The file contains:
Resource identifiers (like VPC IDs, bucket names, etc.)
Resource relationships and dependencies
Computed values and outputs
Provider and metadata information
This allows Terraform to compute accurate diffs during plan and execute safe updates during apply or destroy. Commands like terraform plan and terraform destroy rely entirely on this file.
By default, it lives locally as:
terraform.tfstate
terraform.tfstate.backup
Fine for a solo lab. Not fine for a multi-developer environment.
Architecture at a Glance
Here’s the architecture I used on Day 4:
Terraform CLI: local execution and configuration
AWS S3: remote backend for the
terraform.tfstateAWS resources: VPCs, S3 buckets, etc.
How it fits together:
Backend configuration tells Terraform where to store state.
terraform initsets up the backend and migrates existing state.planandapplyuse the remote state for consistent diffing and changes.

Terraform operates locally as the control plane, but its memory — the state — lives in S3 where it’s shared, durable, and safely accessible.
Setting Up a Remote Backend in Code
Here’s the backend block I used:
terraform {
backend "s3" {
bucket = "aditya-tf-day3-3d879655"
key = "dev/terraform.tfstate"
region = "us-east-1"
encrypt = true
use_lockfile = true
}
}
This tells Terraform to push its state into the S3 bucket under the dev/terraform.tfstate key. encrypt = true ensures encryption at rest. use_lockfile = true introduces native locking so multiple operations don’t collide.
After running:
tf init
Terraform prompted me to migrate my existing local state, then initialized successfully. From this point onward, tf plan and tf apply behave the same, but now with shared state stored in AWS is ideal for any real DevOps pipeline.
Resources and the Code That Matters
After configuring the backend, I created real AWS resources:
provider "aws" {
region = "us-east-1"
}
resource "aws_vpc" "example" {
cidr_block = "10.0.0.0/16"
}
I also created a bucket with a generated suffix for uniqueness:
resource "random_id" "suffix" {
byte_length = 4
}
resource "aws_s3_bucket" "example" {
bucket = "aditya-tf-day3-${random_id.suffix.hex}"
force_destroy = true
}
Two practical lessons here:
Terraform doesn’t need hard-coded names generated IDs to avoid conflicts.
force_destroy = truelets Terraform delete buckets even when objects exist.
This style of writing infrastructure feels natural once you start thinking declaratively: define intent, let Terraform translate it into API calls.
Small Insights That Matter
Terraform’s state file isn’t just a bookkeeping tool it’s the source of truth. With a remote backend, Terraform doesn’t recreate resources unnecessarily because it checks state first. That’s more than convenient; it’s the safety layer that keeps teams from stepping on each other’s work.
Another insight from Day 4: S3 as a backend isn’t just storage. With locking enabled, Terraform avoids race conditions when two users apply changes at the same time. That capability alone makes remote state mandatory for any serious deployment workflow.
Takeaways from Day 4
By the end of the day, I hadn’t just written more HCL I had changed how Terraform relates to infrastructure. Moving state into S3 gave me shared, durable Terraform memory. I saw how backend configuration interacts with AWS during initialization and planning, and I deployed real resources while watching Terraform track them reliably through state.
Day 4 was about mastering state, not just creating resources and that’s a turning point in understanding how Terraform scales beyond a personal lab.
See you tomorrow…